Proof of Time
A semi-verifiable benchmarking framework for evaluating scientific idea judgments.
Why Time Matters
Judging the quality of scientific ideas is hard. Current methods rely on immediate proxies—but true impact takes time to reveal itself. Proof of Time (PoT) solves this by time-partitioning the evaluation: we freeze evidence before a cutoff, ask models to forecast outcomes, and score them when the future arrives.
Key Advantages
⏳ Time-Partitioned
Ground truth arrives naturally as time passes—no manual labeling needed. Models are evaluated against verifiable future outcomes.
📈 Scalable
Evaluation scales automatically without exhaustive expert annotation. Over 30,000 instances spanning four domains.
🔬 Semi-Verifiable
Benchmarks link to real-world signals (citations, awards, leaderboard updates) that become observable post-cutoff.
How It Works
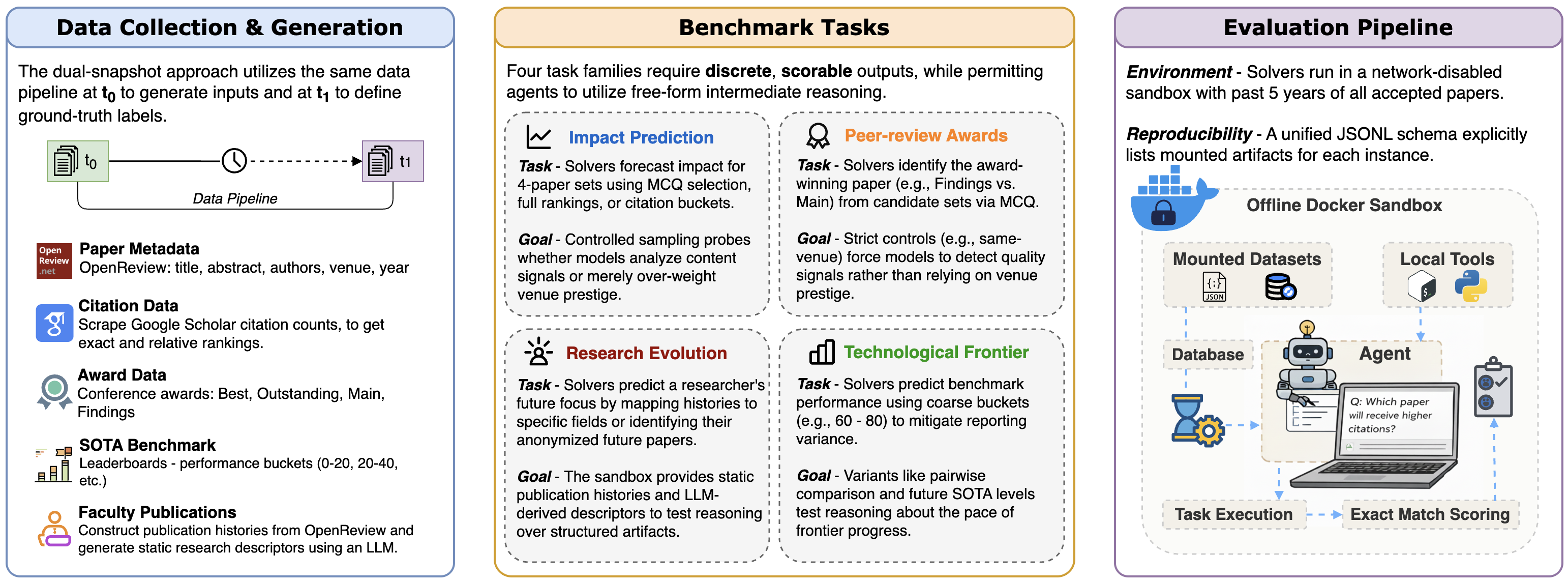
The PoT workflow: Evidence is frozen at a cutoff. Models forecast future outcomes. Ground truth arrives—enabling scalable, verifiable evaluation.
Task Families
Impact Prediction
Forecasting paper influence (citations) from limited cues. Models identify which papers will have higher impact.
Scientific Value
Predicting peer-review awards. Can models align with expert judgments to predict Best Papers?
Research Evolution
Longitudinal reasoning about faculty trajectories. Inferring a researcher's focus shifts.
Technological Frontier
Extrapolating benchmark progress (SOTA) and forecasting future leaderboard metrics.
Key Findings
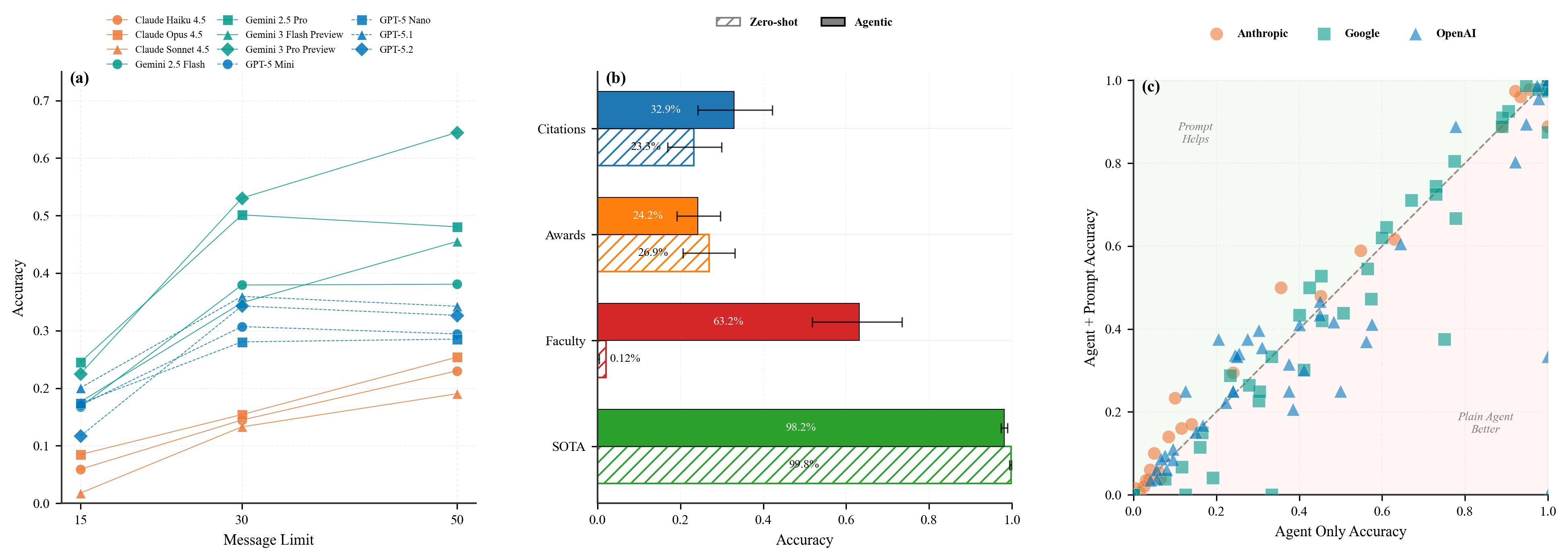
Core Results: Test-time compute scaling and Zero-shot vs Agentic comparisons.
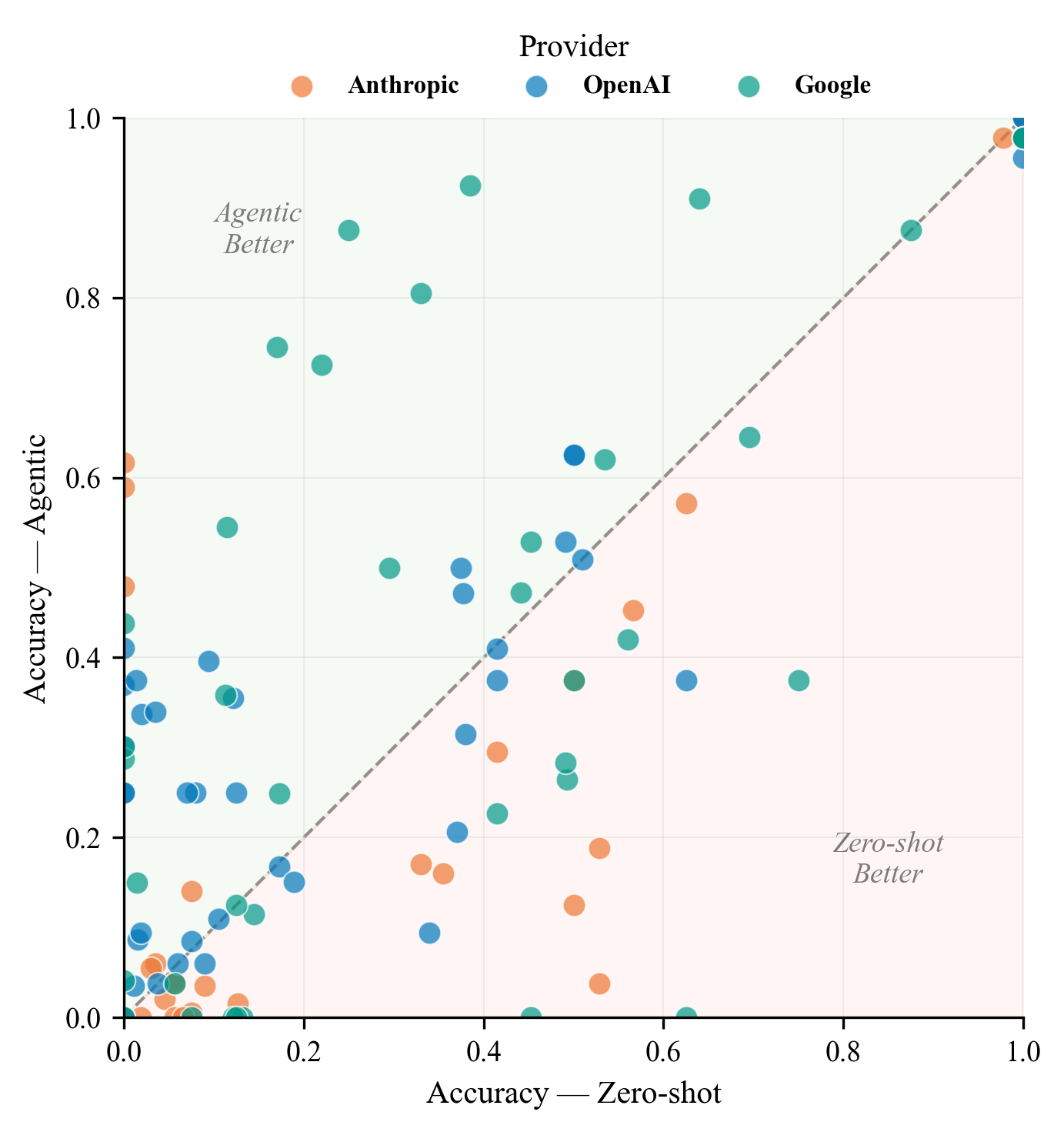
Do Agents Help? Agentic systems generally outperform zero-shot baselines on tasks requiring evidence exploration.
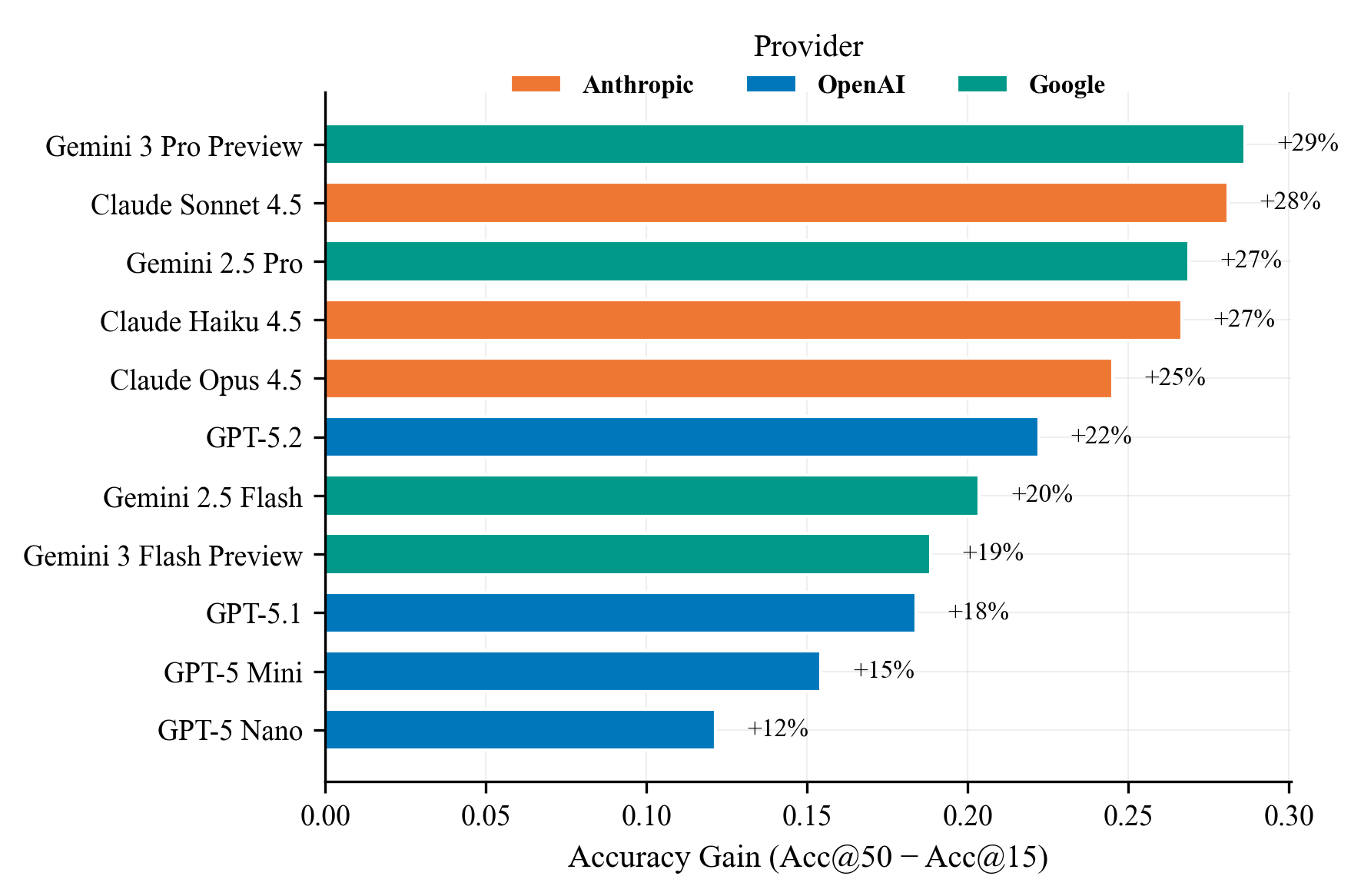
Scaling Benefits: Increasing interaction budgets yields large improvements for Claude models, while others plateau.
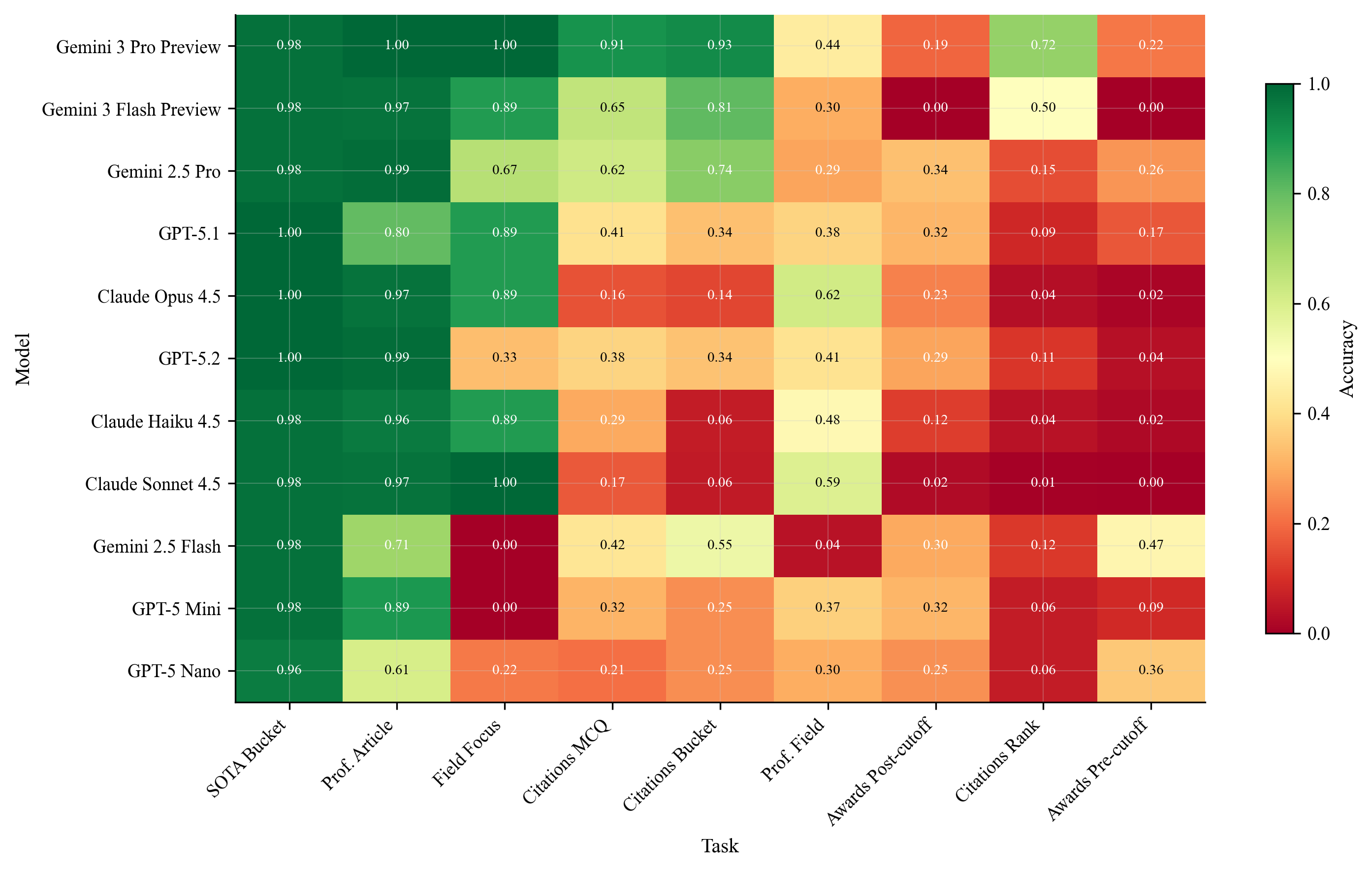
Performance heatmap across different models and tasks at high message limits.